gRPC - Protobuf / Protocol Buffers
Overview:
Protobuf / Protocol Buffers – an interface definition language or interface description language (IDL).
Protobuf is a great way for schema definition and auto-generating source code. It ensures type safety, faster serialization, and deserialization.
SOAP - XML
REST - JSON
gRPC - Protocol Buffer
Problems With JSON:
- No strict schema enforcement. People can easily change the structure to break the contract and it can cause confusion among the team members.
// team 1 expectation
{
"order_id" : 1234
}
// team 2 understanding
{
"orderId" : 1234
}
// team 3 understanding
{
"order":{
"id" : 1234
}
}- JSON is text-based. Human-friendly but not machine friendly. It takes time to serialize and deserialize when we use it for microservices communication.
Protobuf/Protocol Buffers:
Protobuf is Google’s language-neutral, platform-neutral method for deserializing & serializing structured data used to define the contract for the communication between 2 services.
We define the contract in a simple .proto file and we could easily generate source code in any language.
Protocol Buffers – Scalar Types:
Scalar types are basic building blocks in Protocol Buffers using which we could create other complex types.
int32, int64,
bool,
double,
float,
string,
bytes
For example, we have to define a contract for an address that will contain 4 fields in the given order.
message Address {
int32 postbox = 1;
string street = 2;
string city = 3;
string country = 4;
}We can use the Address type defined above to create other Types if we need.
message Person {
string first_name = 1;
string last_name = 2;
int32 age = 3;
Address address = 4;
}Collection:
We can define a person with multiple contact numbers, this way.
message Phone {
int32 area_code = 1;
int64 mobile_number = 2;
}
message Person {
string first_name = 1;
string last_name = 2;
int32 age = 3;
Address address = 4;
repeated Phone contact_numbers = 5;
}Map:
Key and value pairs are defined as shown here.
message Dictionary {
map<string, string> translation = 1;
}Enum:
Protobuf can support enums as well. Various order statuses can be defined as shown here.
enum Status {
PENDING = 0;
IN_PROGRESS = 1;
SUCCESS = 2;
FAILED = 3;
}
message PurchaseOrder {
string product_name = 1;
double price = 2;
int32 quantity = 3;
Status status = 4;
}Default Values:
When we use protocol buffers, they have these default values when any of the fields are not set.

Packages & Options:
By default, all the proto files will have the syntax as proto3. If it is not set, then it is assumed to be proto2.
syntax = "proto3";We can include the below options.
option java_package = "com.abhishek.common";
option java_multiple_files = true;- The package option indicates that when we auto-generate source code for java from proto files, they should be placed under com.abhishek.common package.
- A single .proto file can have multiple message types. But when we generate source code, each message should be a separate class. It is indicated by the multiple files option.
The complete syntax of a proto file would be like this.
syntax = "proto3";
package common;
option java_package = "com.vinsguru.common";
option java_multiple_files = true;
enum Status {
PENDING = 0;
IN_PROGRESS = 1;
SUCCESS = 2;
FAILED = 3;
}
message PurchaseOrder {
string product_name = 1;
double price = 2;
int32 quantity = 3;
Status status = 4;
}- package common; This is for the proto files package.
Importing Types:
- In the below image, I have a common folder that contains multiple proto files

- person.proto might want to use a type defined under a common package which can be done as shown here.
syntax = "proto3";
import "common/address.proto";
package person;
option java_package = "com.vinsguru.person";
option java_multiple_files = true;
message Person {
string first_name = 1;
string last_name = 2;
repeated common.Address address = 3;
}Need For gRPC:
Microservices are the popular way to design distributed systems. A big monolith application is broken down into multiple independent Microservices. Microservices do not come alone. There will be always more than 1 service. These Microservices communicate with each other mostly with REST using HTTP/1.1 protocol by exchanging JSON.
For example: If a user tries to send a request to order a service to order a product, the order service might internally send multiple requests to other services to fulfill the request.

REST is simple and very easy to use. REST is great for browsers. Easy to test our APIs. Developers love this. So we always use REST style for our inter-microservices communication. However, it has the following issues.
- HTTP/1.1 is textual & Heavy. Microservices exchange information by using huge JSON payloads.
- HTTP is stateless. So additional information is sent via headers that are not compressed.
- HTTP/1.1 is unary – that is – you send a request and get a response. You can not send another request until you receive the response.
- HTTP request requires a 3-way message exchange to set up a TCP connection first which is time-consuming.
This all can affect the overall performance of our Microservices. REST is good between the browser and back-end. But we need something better than REST for inter-microservices communication to avoid above mentioned issues.
Microservices are the popular way to design distributed systems. A big monolith application is broken down into multiple independent Microservices. Microservices do not come alone. There will be always more than 1 service. These Microservices communicate with each other mostly with REST using HTTP/1.1 protocol by exchanging JSON.
For example: If a user tries to send a request to order a service to order a product, the order service might internally send multiple requests to other services to fulfill the request.
REST is simple and very easy to use. REST is great for browsers. Easy to test our APIs. Developers love this. So we always use REST style for our inter-microservices communication. However, it has the following issues.
- HTTP/1.1 is textual & Heavy. Microservices exchange information by using huge JSON payloads.
- HTTP is stateless. So additional information is sent via headers that are not compressed.
- HTTP/1.1 is unary – that is – you send a request and get a response. You can not send another request until you receive the response.
- HTTP request requires a 3-way message exchange to set up a TCP connection first which is time-consuming.
This all can affect the overall performance of our Microservices. REST is good between the browser and back-end. But we need something better than REST for inter-microservices communication to avoid above mentioned issues.
gRPC:

gRPC is an RPC implementation/framework from Google for inter-microservices communication. Google has been using this for more than 15 years (the internal name is Stubby).
The call will be made as we would normally invoke a local method call. It follows the client-server model. A client sends a request to the server by invoking a method on the remote server and exchanging messages. gRPC provides a well-defined interface and type safety.
gRPC is faster than REST. We achieve this performance gain by switching to gRPC because of these 2 important reasons along with other in-built tools.
- HTTP/2
- Protocol Buffers

gRPC is an RPC implementation/framework from Google for inter-microservices communication. Google has been using this for more than 15 years (the internal name is Stubby).
The call will be made as we would normally invoke a local method call. It follows the client-server model. A client sends a request to the server by invoking a method on the remote server and exchanging messages. gRPC provides a well-defined interface and type safety.
gRPC is faster than REST. We achieve this performance gain by switching to gRPC because of these 2 important reasons along with other in-built tools.
- HTTP/2
- Protocol Buffers
By combining the above HTTP/2 and Protocol Buffers, gRPC becomes a better choice for inter-microservices communication.

gRPC API Types:
REST by default is unary. We send a request and get a response.
But gRPC supports streaming requests and responses along with unary APIs.
- Unary: This is a regular blocking request and response call.

- Client Streaming: The client keeps on sending a request to the server by using a single TCP connection. The server might accept all the messages and sends a single response back.
- Use case: File upload functionality

- Server Streaming: The server sends multiple messages to the client via a single TCP connection.
- Use case: Pagination or Server pushes periodic updates to the client asynchronously.

- Bi-Directional Streaming: The client and Server can keep on sharing messages via a single TCP connection.
- Use case: Chat application or GPS or Client & server have to work together in an interactive way to complete a task

Service Definition:
Let's assume that we need to develop a Calculator application that provides the following functionalities.
- Unary: Finding factorial for the given number
- Client Streaming: The client sends multiple numbers and the server has to sum them all
- Server Streaming: The client sends a number to the server for which Server has to find all the factors. For example, If the client sends 6, the server will respond with 2 and 3.
- Bi-Directional Streaming: The client sends multiple numbers to the server. The server has to check them one by one. If the number is prime, the server will pass it back to the client.
Let's come up with a service contract using Protocol buffers as shown below.
syntax = "proto3";
package calculator;
option csharp_namespace = "CalculatorServerProto";
message Input {
int32 number = 1;
}
message Output {
int64 result = 1;
}
service CalculatorService {
// unary
rpc findFactorial(Input) returns (Output) {};
// server stream
rpc getAllFactors(Input) returns (stream Output) {};
// client stream
rpc sumAll(stream Input) returns (Output) {};
// bi-directional stream
rpc findPrime(stream Input) returns (stream Output) {};
}gRPC Unary API:
This call can either be a blocking synchronous call or a non-blocking asynchronous call. Let’s take a look at both options.
Sample Application:
We need to implement a calculator application in which our back-end server has to find the factorial for the given number.
findFactorial is going to be the method to be implemented on the server side. By default, if we do not use any stream keyword in the rpc, it is Unary.
syntax = "proto3";
package calculator;
option java_package = "com.vinsguru.calculator";
option java_multiple_files = true;
message Input {
int32 number = 1;
}
message Output {
int64 result = 1;
}
service CalculatorService {
// unary
rpc findFactorial(Input) returns (Output) {};
}gRPC Blocking Unary Call:
Stub: The client will use either a blocking stub / a non-blocking stubgRPC Async Unary Call:
If the request is time-consuming, we can make this request to be completely non-blocking by using an asynchronous stub.
The client does not wait for the response to come back.
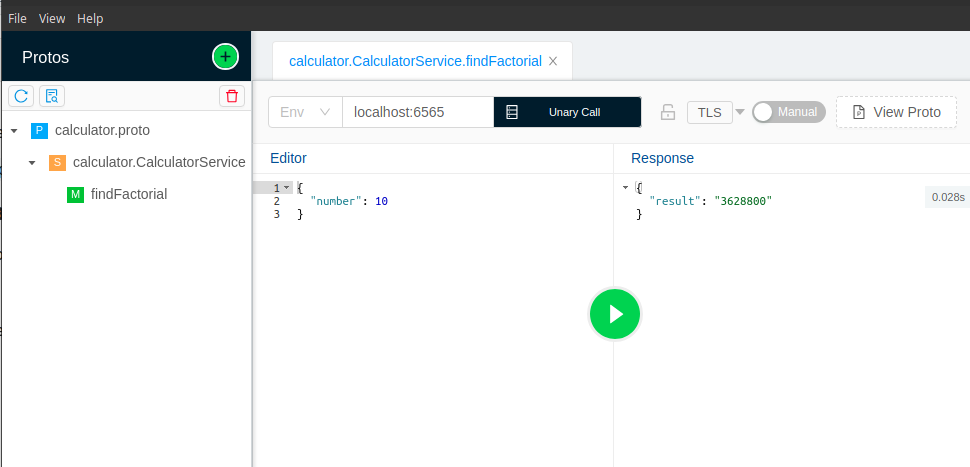
BloomRPC:
It is very very easy to test REST-based APIs by using postman/web browsers. But testing gRPC might not look easy so far. It seems to require writing separate code.
Resolve HttpContext in gRPC methods:
The gRPC API provides access to some HTTP/2 message data, such as the method, host, header, and trailers. Access is through the ServerCallContext the argument passed to each gRPC method:
public class GreeterService : Greeter.GreeterBase { public override Task<HelloReply> SayHello( HelloRequest request, ServerCallContext context) { return Task.FromResult(new HelloReply { Message = "Hello " + request.Name }); } }
ServerCallContext doesn't provide full access to HttpContext in all ASP.NET APIs. The GetHttpContext extension method provides full access to the HttpContext representing the underlying HTTP/2 message in ASP.NET APIs:
public class GreeterService : Greeter.GreeterBase { public override Task<HelloReply> SayHello( HelloRequest request, ServerCallContext context) { var httpContext = context.GetHttpContext(); var clientCertificate = httpContext.Connection.ClientCertificate; return Task.FromResult(new HelloReply { Message = "Hello " + request.Name + " from " + clientCertificate.Issuer }); } }
.proto file message
message Person {
string name = 1;
int32 id = 2; // Unique ID number for this person.
string email = 3;
enum PhoneType {
MOBILE = 0;
HOME = 1;
WORK = 2;
}
message PhoneNumber {
string number = 1;
PhoneType type = 2;
}
repeated PhoneNumber phones = 4;
google.protobuf.Timestamp last_updated = 5;
}
// Our address book file is just one of these.
message AddressBook {
repeated Person people = 1;
}
The " = 1", and" = 2" markers on each element identify the unique "tag" that field uses in the binary encoding. Tag numbers 1-15 require one less byte to encode than higher numbers, so as an optimization, you can decide to use those tags for the commonly used or repeated elements, leaving tags 16 and higher for less-commonly used optional elements. Each element in a repeated field requires re-encoding the tag number, so repeated fields are particularly good candidates for this optimization.
If a field is repeated, the field may be repeated any number of times (including zero). The order of the repeated values will be preserved in the protocol buffer. Think of repeated fields as dynamically sized arrays.








